TigerBeetleの「Index, Count, Offset, Size」という記事タイトルを見て、シンプルだけど実務で刺さるテーマだと思いました。ページングや集計はどのサービスにもありますが、設計を誤ると地味に遅くなり続けます。最初は問題なくても、データが増えるほどレイテンシが跳ねる。多くのチームが通る落とし穴です。
私も以前、OFFSET中心の実装で一覧APIを作って、運用後に急激に遅くなった経験があります。クエリ自体は正しくても、件数が増えるとスキャン量が増え続けるんですよね。だから最近は、画面要件を先に決めてから、IndexとCountの取り方を設計するようにしています。
Index Count Offset Size設計の基本
まず、INDEXは「検索条件と並び順のセット」で考えるのがコツです。単に列へインデックスを貼るだけでは不十分で、実際に使うWHEREとORDER BYに合わせる必要があります。ここを外すと、インデックスがあるのに遅い、という状態になりがちです。実行計画を確認する習慣はやはり大事ですね。
COUNTは、リアルタイム厳密値が本当に必要かを見直すと改善しやすいです。管理画面なら概算で十分なこともありますし、キャッシュや非同期更新で体験を守れる場合もあります。常に正確な総件数を同期で取りにいく設計は、想像以上に重いです。
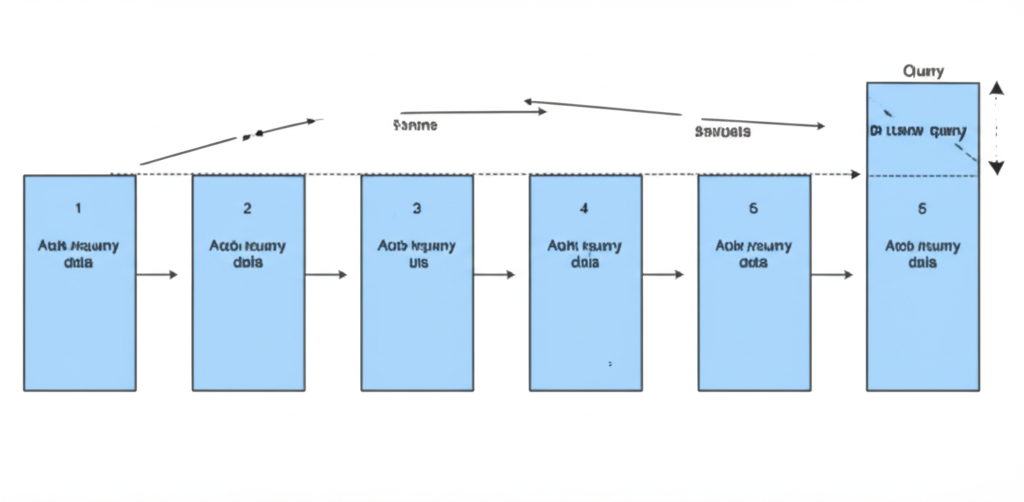
OFFSET依存を減らす実装パターン
深いページまで行くUIでは、OFFSETよりカーソル方式の方が安定します。特に時系列データでは、最終取得位置をキーにした方がコストが読みやすいです。結果の欠落や重複を避けるために、並び順の一意性を担保することも忘れたくないポイントです。
API設計では、ページサイズ上限を先に固定しておくと運用が楽になります。ユーザー都合で巨大サイズを許すと、ピーク時にDBが詰まりやすいです。ここはAIエージェント基盤の負荷設計と似ていて、無制限を避けるだけで障害率が下がります。
実務でのチェック項目
実装後は、実行計画、P95レイテンシ、キャッシュヒット率の3点を継続監視するのが現実的です。開発時に速くても、データ分布が変わると突然遅くなるケースがあります。だからこそ、最初から観測指標を埋め込んでおく方が安全です。
Index・Count・Offset・Sizeは地味な単語ですが、ここを丁寧に詰めるとサービス全体の体感速度が安定します。派手な最適化より、土台の設計を崩さない。結果として運用コストも下がるので、早い段階で押さえておきたいテーマだと思います。
参考: TigerBeetle Blog / Use The Index, Luke! / PostgreSQL EXPLAIN / 開発運用関連記事